OCHA-RAG: Retrieval-Augmented Generation System
A humanitarian document analysis system that allows OCHA analysts to upload PDF collections, query them in natural language, and generate structured, citation-backed analytical reports using advanced AI and retrieval technologies.
Overview
OCHA-RAG is an advanced document analysis system built specifically for humanitarian analysts working with the United Nations Office for the Coordination of Humanitarian Affairs (OCHA). The system leverages retrieval-augmented generation (RAG) technology to enable natural language querying of large PDF document collections.
Using state-of-the-art AI technologies including LlamaIndex orchestration, Haystack retrieval, and GPT-4 generation, the system produces structured analytical reports with preserved citations, making it invaluable for humanitarian research and decision-making processes.
Key Features
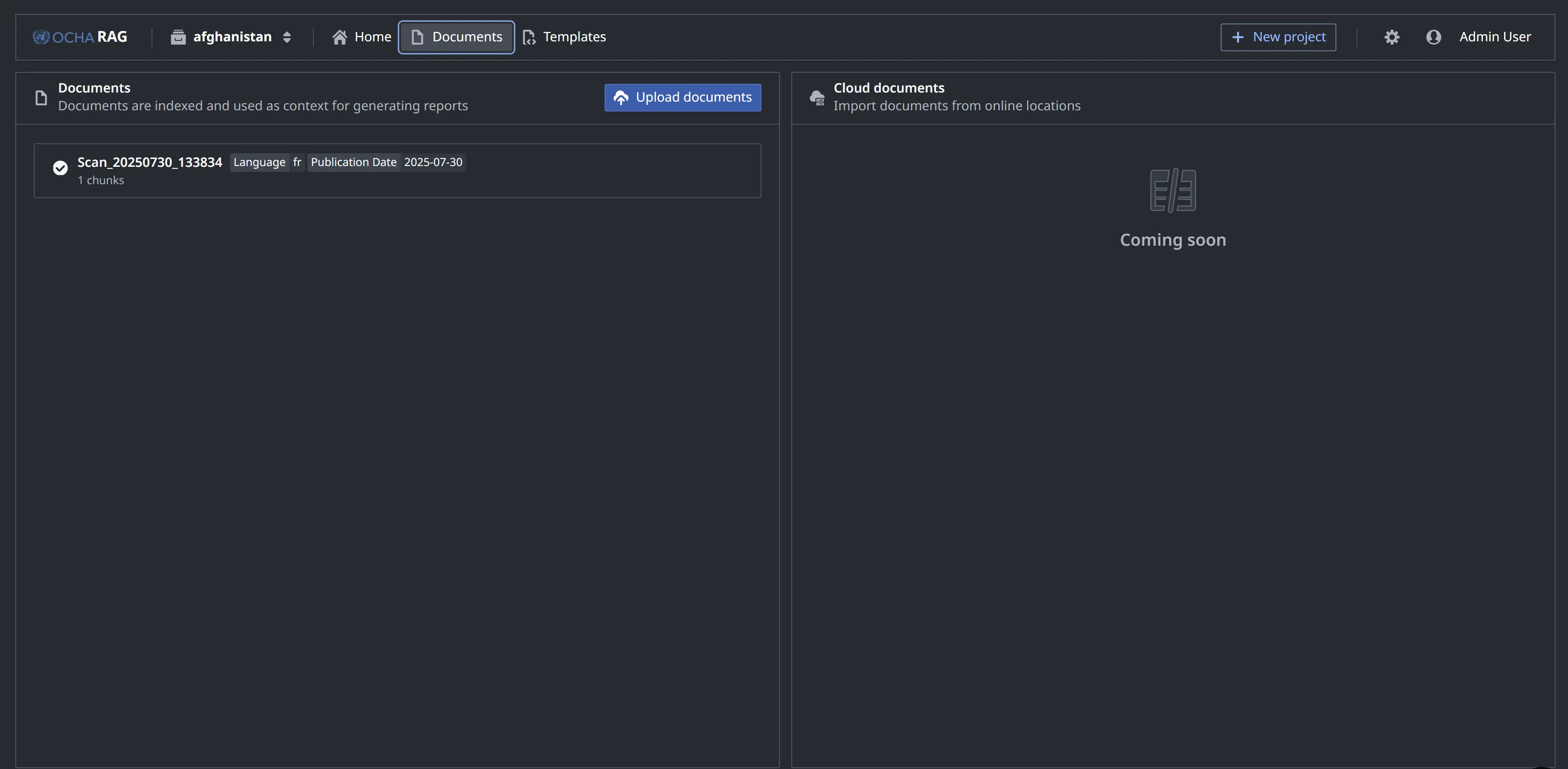
Document Ingestion
LlamaParse API for PDF extraction with intelligent chunking and PostgreSQL+pgvector storage
Vector Retrieval
Haystack 2.x with vector similarity search and optional reranking for accurate results
AI Report Generation
LlamaIndex orchestration with GPT-4 via LiteLLM for structured analytical reports
Multi-language Support
Process documents in English, French, Arabic, and German for global operations
Office-level Isolation
Secure data separation per humanitarian office ensuring confidentiality
Citation Tracking
Automatic page-level references in all generated reports for verification
Professional Export
Generate reports in Word (.docx) and PDF formats with preserved formatting
React Frontend
Modern interface for document upload, natural language queries, and report generation
Technical Architecture
The system employs a sophisticated pipeline architecture combining multiple AI technologies. Documents flow through LlamaParse for extraction, are chunked and vectorized, then stored in PostgreSQL with pgvector extension for efficient similarity search. Query processing uses Haystack's retrieval capabilities, while LlamaIndex orchestrates the final report generation with GPT-4.
PDFs → LlamaParse → Chunker → Haystack → PostgreSQL+pgvector
↓
Query → Haystack Retriever → LlamaIndex → Structured Report → Export Backend Stack
- • Python with FastAPI for REST endpoints
- • PostgreSQL with pgvector for vector storage
- • LlamaParse for intelligent PDF extraction
- • Haystack 2.x for retrieval pipeline
AI Integration
- • LlamaIndex for RAG orchestration
- • GPT-4 via LiteLLM proxy
- • Vector similarity search with reranking
- • Docker-based deployment
Workflow
1. Document Upload
Analysts upload PDF collections through the React interface, which are processed by LlamaParse for text extraction
2. Vectorization & Storage
Extracted text is chunked, vectorized, and stored in PostgreSQL with pgvector for efficient retrieval
3. Natural Language Query
Users query the document collection in natural language, with Haystack performing vector similarity search
4. Report Generation
LlamaIndex orchestrates GPT-4 to generate structured analytical reports with preserved citations and export to Word/PDF
Project Status
The system is currently in pilot phase and being tested in various natural disaster and multi-year impact conflict situations, providing real-world validation of its capabilities for humanitarian analysis and decision-making.